今回はPythonのpandasとnumpyで度数分布表を作る方法を考えてみました。
関数やコードの紹介がメインなので度数分布表が何かとい解説は別記事でまとめたいと思います。

度数分布表で使う関数
pandasとnumpyを使うのでインポートしておきます。
|
1 2 |
import pandas as pd import numpy as np |
| 関数 | 意味 |
|---|---|
np.histogram() | 階級(bin)と度数(hist)を返す binの数はhistより一つ多いので注意 公式ページはコチラ |
numpy.histogram_bin_edges() | データに対応するbinの数を返す。bins='sturges'でスタージェンスの公式を適応今回は使っていません。 公式ページはコチラ |
np.cumsum() | 累積和の計算 公式ページはコチラ |
np.cumprod() | 累積積の計算(使わないけどおまけ) 公式ページはコチラ |
データフレームの作成も行っています。詳しくは以下の記事でまとめています。
データ分析ではPythonのpandasが有名ですよね。とくに大量のデータを処理できるデータフレーム(DataFrame)は使いこなせると便利です。 そこで今回は、データフレームの作成方法を紹介していきたいと思います。 [it[…]

度数分布表を自動作成する関数
関数のコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
def frequency_table(data, stur=False): data_len = len(data) print('データ数:', data_len) #スタージェンスの公式でbinの数を求める if stur is True: b = round(1 + np.log2(data_len)) hist, bins = np.histogram(data, bins=b) else: hist, bins = np.histogram(data) #データフレーム作成 df = pd.DataFrame( { '以上': bins[:-1], '以下': bins[1:], '階級値': (bins[:-1]+bins[1:])/2, '度数': hist } ) #相対度数の計算 df['相対度数'] = df['度数'] / data_len #累積度数の計算 df['累積度数'] = np.cumsum(df['度数']) #累積相対度数の計算 df['累積相対度数'] = np.cumsum(df['相対度数']) return df |
引数は度数分布表の作成に使うdataとスタージェンスの公式を利用するかどうかのstarです。
スタージェンスの公式は適切な階級数を導くためのものです。
以下で実行結果の違いを確認できます。
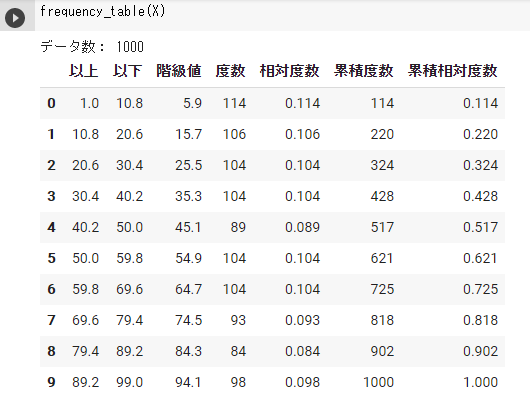
スタージェンスの公式なし(デフォルト)
|
1 2 3 |
X = np.random.randint(1, 100, 1000) frequency_table(X) |
スタージェンスの公式あり
|
1 |
frequency_table(X, stur=True) |
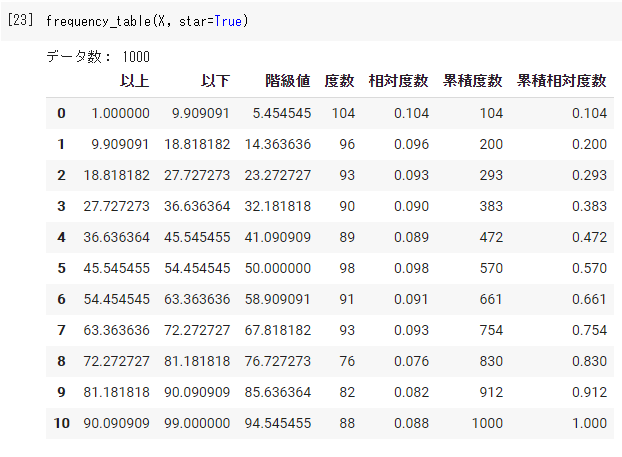
小数になってしまって見にくいですね。
以下では度数分布表を自動作成する関数の解説をしています。
階級と階級値
- 階級はbinsで確認
- binsの数はhistの数より一つ多い
例えば、次のように出てきたとき
bins=[1, 2, 3, 4, 5]
hist=[10, 20, 10, 15]
1~2の間に10個、2~3の間に20個あるという意味になります。
つまり、binsには階級の上限と下限が含まれるのでhistよりも長さが一つだけ大きくなります。
もっと簡単に言うと、1~5で差は5-1=4ですが、数字の数は1~5の5つありますよね。
このようにbinsが一つ多いので階級値はスライスして求めています。
|
1 |
(bins[:-1]+bins[1:])/2 |
これはbinsがリストではなく配列なのでできる計算方法です。
ブロードキャストという性質を使っています。
この性質に関しては別の記事で解説します。
度数と相対度数
- 度数はhistで確認
- 相対度数は度数を合計で割る
- 相対度数の合計は1
|
1 2 3 4 |
data_len = len(data) #相対度数の計算 df['相対度数'] = df['度数'] / data_len |
DataFrameやSeriesにはブロードキャストという性質があるので、セルごとに割り算ができます。
累積度数と累積相対度数
- 累積度数は度数に累積和
np.cumsum()を使う - 累積相対度数は相対度数に累積和
np.cumsum()を使う
|
1 2 3 4 5 |
#累積度数の計算 df['累積度数'] = np.cumsum(df['度数']) #累積相対度数の計算 df['累積相対度数'] = np.cumsum(df['相対度数']) |
引数の累積和を計算してくれます。
DataFrameの列を追加する方法は以下の記事にまとめています。
今回はDataFrameの行や列を追加・削除する方法を紹介します。リストや配列、Seriesを使うことで可能になります。 列の追加に関するドキュメントはコチラ DataFrameの作成方法は以下の記事をご覧ください [s[…]

まとめ
今回は度数分布表を自動で作成する関数を自作してみました。
案外簡単に作れるんだなと思いましたが、もっとシンプルにできそうですね。
スタージェンスの公式を使ったときに小数になるのをどうにか解消するのが課題です。